Developing, debugging and testing a database application are common tasks for data-intensive organizations. Private companies, medical and financial corporations, and even government authorities are the largest customers for the database developers. Commercial and trade secrets must be protected from a business security standpoint. Privacy policies and government legislations legally restrict the possibilities of organizations to provide real data to database developers, protecting subjects whose information makes the content of a database. Violating such policies and legislations can cause bad publicity and have negative legal consequences altogether.
Why provide real data to the developer at all? The answer is simple: the developers need realistic sample data in order to develop the database, optimize its performance and eliminate possible bugs. Given a sample too small or too far away from whatever data is actually going to be used, the developers make poor decisions, which leads to a non-optimal performance or consistent problems in usability and reliability of a database.
The paradox is obvious: one can't give supply the developers with any real data without facing negative publicity and legal consequences, while at the same time a database can't be realistically developed without the data. The solution to this dilemma is data scrambling.
Data Masking Process Definition
Data scrambling replaces real data with fake yet realistic records. If a record in a real financial database reads "John Doe, balance $10,000, account #000", a data scrambler will replace the record with something random yet realistic, e.g. "Mae Smith, balance $2,345, account #123", protecting the identity of the customer by changing the name, at the same time protecting the security of the financial institution by randomly changing the balances of the customers' accounts.
|
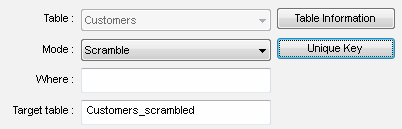
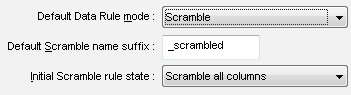
Scrambling is a process of transferring data from the production database into a test mode database. Data scrambling, when used properly, removes sensitivity from the sensitive information, which results in realistically looking data records preserving the original keys and relationships of the real database. Using scrambled data allows giving out a perfectly usable fake database to the developers, allowing the developers to perform full-scale optimization and testing of the resulting application without compromising the system database. DTM Data Generator implements data scrambling in a correct way. Its scramble mode allows creating a new scrambled table in the existing or new database. The scrambled table contains modified information such as changed names, credit card numbers, medical records, and so on. The substitute records are not looking as if they were a random set of characters. Instead, names are replaced with other names, and credit card numbers are replaced with the numbers of the same length and of the same structure. The scrambling related options make the process more flexible. For example, the user can select "Scramble no columns" as default mode. In this case only manually specified columns will be scrambled by the project. The table name suffix can be added to the target table automatically in case the scrambled table stored in the same database. |
 |