DTM Data Generator is a software that was designed to populate test databases by high-quality and realistic sample data. To keep data integrity it analyzes database schema for master-details relationships and constraints. For example, if constraint defines (UnitPrice>1) rule the software will generate numbers greater than 1 only.
Of course, the user is able to define additional limitations for data generation rules manually: change fill method, define ranges or set NULL value share. It is suitable for small database structures but too expensive for complex databases with thousands of tables.
The test data by example feature can help to make the data set much better. It analyzes an existing database with the same structure to find:
- Value limitations.
- Lists of predefined values like ('M','F') for gender column.
- Value dependencies and sequences.
- Templates or patterns for value sets.
This function is available as a step of standard Wizard of DTM Data Generator. It offers two options: use the current database as an example or external database. The first mode is most suitable for "append" mode. This mode allows users to add test data to existing tables with data. The generator will analyze table and append rows like existing content.
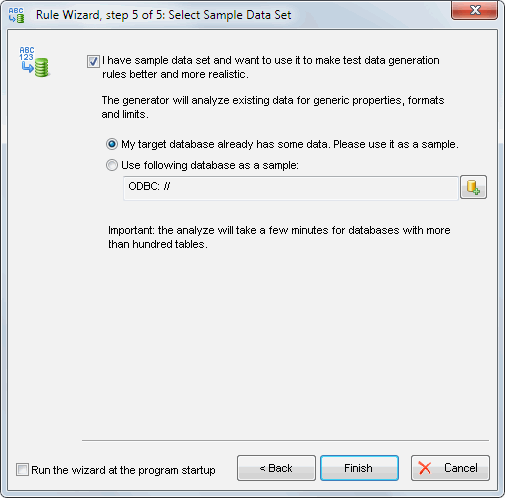
The second mode (i.e. another database) is suitable if the user already has a small production database and want to create large scale one for testing purposes: performance testing, load testing, etc. In this mode, the software analyzes external database and creates optimal data generation rules.
Let's review data properties that the existing data analyzer can use to make mentioned rules better. The simplest property is a minimum and maximum value of the sequence of numbers or minimal and maximal length of the set of strings. Of course, both properties also applicable to date and time values.
The next property is incremental. The data generator finds monotonous sequences of numeric data and identifies a step between neighbors. At the moment, the software can't identify incremental dates and times but we plan to add this option to future releases of the software product.
For any set of string values the analyzer finds capitalization properties: does the string contain upper letters only, does it start from an upper letter, etc. Also, the data generator analyzes the sequence of strings for well-known data sets. With this algorithm, it can find names, e-mails, etc.
The last and most complex set of properties is data template. The template is a set of repeatable parts of each value of the set. For example, a sample phone number can have +N NNN NNNNNN format as well as (NNN) NNN-NNNN format. Analyzing the each template frequency the test data by example engine produces rule most close to original data.
To addition of mentioned properties, the engine finds a frequency of NULL values and empty values. This parameter can make output data more realistic.
The test data by example engine is a powerful tool that helps users to increase data quality without extra efforts or manual database structure review.