In this part, we will describe a few ideas about test data management plan implementation. Please refer to the previous part of the article for detailed information about the plan.
|
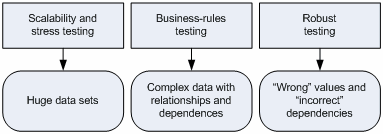
The first idea is about a number of required data sets or databases. How many test data sets do you need?
The second idea describes data complexity that you really need. We recommend analyzing existing test cases and test packages. |
|
The next usual problem is how to get test data: should the company use in-house solution, develop a new one or use third party tool?
In most cases, the answer depends on available resources. If the company has engineers and developers who
can create test data generation scripts without third party tools and the total cost seems acceptable - it is a perfect way.
This way guarantees flexibility but requires a lot of time for development. The alternate way is to create test data using
"test data generation" software. It is a fast way but requires some kind of learning or adaptation. Also, the company must have enough budget to order the software.
|
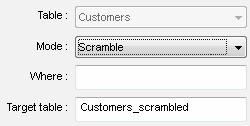
From time to tome companies use customer's data for testing purposes. We do not recommend to do that without data masking or scrambling. Even you don't collaborate with offshore development teams there is a risk of the data compromise. However, modern test data generators offer data scrambling feature that replaces critical data (names, account numbers, etc) to randomly generated values. A few words about test data lifecycle. The company should use only actual sets of test data. That means the QA team has to rebuild test data if the goals, test cases or something else changed. It is a good idea to review test data arrays or databases after each modification of the test data management plan. It guarantees that all interested parties have right (correct, actual, etc) test data. |
|
The next part of the article will discuss personal roles in the test data management.