The development of modern information systems implies the use of programs that are constantly competing for resources. Factors that influence the work of a system under stress are taken into account in its design and traced during the whole process of development. Therefore, stress testing is important and essential for evaluating the quality of software.

We will tell you how to make stress testing easier and more efficient using available tools. First of all, let us classify the tasks that can be important during testing:
- Executing queries in the database or calling the application without changing database contents. This class also includes OLAP operations. These tasks allow you to evaluate the efficiency of the data model, index arrangement, relationships, etc.
- Loading massive data to the database. This class allows you to evaluate the work of an application or a server when data is being entered from more than one workstation and also to evaluate how effectively triggers are implemented and work.
- Executing complex queries that involve data modification in the database both directly (using update operations) and with the help of stored procedures. Let us also include operations of single data input and deletion operations into this class. All these operations are actually OLTP operations permitted by the application.
Evidently, a complex and realistic stress test is a set of manifold tasks that belong to different classes.
For example, suppose an application is designed to work with information entered manually from ten client workstations as separate inputs (it represents company employees working with the database at the same time). Bulk data loading will be done from one computer (it will represent data coming from the company's clients in the machine format). Five workstations will execute complex analytic queries to the database with each query lasting from several minutes to several dozen minutes.
To simulate this load we should prepare:
- a set of standard statements that will be called from ten workstations.
- a sufficient set of realistic test data for loading.
- texts of queries for client workstations of the last type
Value Files with Test Data
Since it is impossible to automate the first and the third items (the development of queries requires the knowledge of the logic and peculiarities of the application to be tested), let us dwell on the second data set and then move on to automating the testing process itself. DTM Data Generator perfectly copes with the second task by quickly generating realistic datasets even with minimum settings. After the data is generated, there are two possible ways. The first one is when DTM Data Generator tests data loading itself. However, besides loading the generated data into the database, DTM Data Generator can save it as a set of insert statements or plain text files with a random field separator. In the second case, it will only produce test data that will be loaded with a special stress testing utility called DTM DB Stress.
Each approach has its advantages and disadvantages. The advantage of the first approach is that the operation is fully automatic. But in this case, it is much more difficult to get the overall statistics of executing various tasks during the test.
It is possible in the second approach, which is much more flexible. You can use both text files and generated scripts, as well as combine these two methods for different tasks. However, in this case, you will have to configure the interaction of these two programs manually by specifying data files and references to their fields.
Let us now see the process of creating a test project for DTM DB Stress in detail. A project includes any number of tasks and each of them can be run as one or several instances (executed as separate threads).
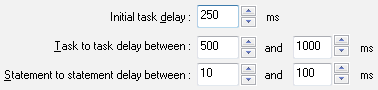
Our example will have three tasks with 10, 1 and 5 instances respectively. It is clear that several utility copies in different network segments with similar or different projects should be run to make the test more adequate and efficient and also to take into account the peculiarities of the company's network infrastructure. To make the test more realistic, the program allows you to set a lot of properties for each task, such as time between iterations (in our example the delay for the first and the third task types should be set to 0.5 seconds, as people do not usually execute queries without a pause), the total number of iterations, task priority, etc.
How does the program use external data for tests? To make it do it, you can not
only specify regular SQL statements (such tasks are called static) but also use
templates with parameters while describing tasks. Templates use structures like ?1, ?2, etc.
that will be replaced with external data that has the corresponding number in the
corresponding file.
This mechanism is very flexible because not only an integer or a string but also a
part of an SQL statement or a whole statement can be such a parameter. For example,
if you insert a string like "select * from ?1 ?2 ?3" into your template and organize
your data file like this:
MyTable1|where|A>5
Table2|order by|Column2
The first statement will contain a where clause, and the second one will do the sorting.
And the query itself will be executed from different tables.
There are three ways of using a file with parameters. In the first case, all instances of
a task use the file with parameters independently and select its lines randomly. This is
the default variant.
In the second case, each thread uses its own separate line with parameters. In this case the number of lines in the file must be equal or more than the number of threads, otherwise, the program will show an error message. This method allows you to simulate the different activity on different workstations.
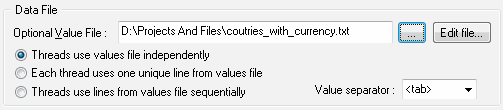
The third method implies taking lines with data one by one. When all lines in the file
are taken, the program starts scanning the file from the first line again.
To check how effective the data are fetched to the client part of the information system,
you can specify if the result strings and their quantity should be fetched for each task.
This method will also show how heavily the network will be loaded in a case with large result sets.
If you are creating several tasks of the same type, it makes sense to change the default
task properties in the Settings window - you will be able to create tasks adapted to a certain
application faster. Another convenient feature of working with tasks for debugging and testing
is enabling/disabling them temporarily. Use the context menu to do it.
Now let us see how you can influence the work of a test project in progress. The program allows you to:
- Pause one or several selected task threads. It represents the situation when some employees stop working with the database for a while. You can also pause all tasks to analyze how effectively the server will process the queue of queries it already has.
- Interrupt one or several selected tasks.
The program offers three ways of displaying the process of executing a test project:
execution console, text, and graphic statistics. The console shows the current process
of executing all running instances of all tasks and the total performance of the package.
Text and graphic statistics show the performance at the time intervals you specify (30 seconds
by default). The current versions provide statistics for the first five objects which can
be either tasks (the total information on all the task instances is shown in this case) or threads of a separate task.
The statistical information helps to easily find bottlenecks in the designed application and to solve such aspects of the problem as performance degradation in time and its periodic instability.